一、简单概述
最近在了解ELK做日志采集相关的内容,这篇文章主要讲解通过filebeat来实现日志的收集。日志采集的工具有很多种,如fluentd, flume, logstash,betas等等。首先要知道为什么要使用filebeat呢?因为logstash是jvm跑的,资源消耗比较大,启动一个logstash就需要消耗500M左右的内存,而filebeat只需要10来M内存资源。常用的ELK日志采集方案中,大部分的做法就是将所有节点的日志内容通过filebeat送到kafka消息队列,然后使用logstash集群读取消息队列内容,根据配置文件进行过滤。然后将过滤之后的文件输送到elasticsearch中,通过kibana去展示。
filebeat介绍
Filebeat由两个主要组成部分组成:prospector和 harvesters。这些组件一起工作来读取文件并将事件数据发送到您指定的output。
什么是harvesters?
harvesters负责读取单个文件的内容。harvesters逐行读取每个文件,并将内容发送到output中。每个文件都将启动一个harvesters。harvesters负责文件的打开和关闭,这意味着harvesters运行时,文件会保持打开状态。如果在收集过程中,即使删除了这个文件或者是对文件进行重命名,Filebeat依然会继续对这个文件进行读取,这时候将会一直占用着文件所对应的磁盘空间,直到Harvester关闭。默认情况下,Filebeat会一直保持文件的开启状态,直到超过配置的close_inactive参数,Filebeat才会把Harvester关闭。关闭Harvesters会带来的影响:
file Handler将会被关闭,如果在Harvester关闭之前,读取的文件已经被删除或者重命名,这时候会释放之前被占用的磁盘资源。 当时间到达配置的scanfrequency参数,将会重新启动为文件内容的收集。 如果在Havester关闭以后,移动或者删除了文件,Havester再次启动时,将会无法收集文件数据。 当需要关闭Harvester的时候,可以通过close*配置项来控制。什么是Prospector?
Prospector负责管理Harvsters,并且找到所有需要进行读取的数据源。如果input type配置的是log类型,Prospector将会去配置度路径下查找所有能匹配上的文件,然后为每一个文件创建一个Harvster。每个Prospector都运行在自己的Go routine里。
Filebeat目前支持两种Prospector类型:log和stdin。每个Prospector类型可以在配置文件定义多个。log Prospector将会检查每一个文件是否需要启动Harvster,启动的Harvster是否还在运行,或者是该文件是否被忽略(可以通过配置 ignore_order,进行文件忽略)。如果是在Filebeat运行过程中新创建的文件,只要在Harvster关闭后,文件大小发生了变化,新文件才会被Prospector选择到。
filebeat工作原理
Filebeat可以保持每个文件的状态,并且频繁地把文件状态从注册表里更新到磁盘。这里所说的文件状态是用来记录上一次Harvster读取文件时读取到的位置,以保证能把全部的日志数据都读取出来,然后发送给output。如果在某一时刻,作为output的ElasticSearch或者Logstash变成了不可用,Filebeat将会把最后的文件读取位置保存下来,直到output重新可用的时候,快速地恢复文件数据的读取。在Filebaet运行过程中,每个Prospector的状态信息都会保存在内存里。如果Filebeat出行了重启,完成重启之后,会从注册表文件里恢复重启之前的状态信息,让FIlebeat继续从之前已知的位置开始进行数据读取。
Prospector会为每一个找到的文件保持状态信息。因为文件可以进行重命名或者是更改路径,所以文件名和路径不足以用来识别文件。对于Filebeat来说,都是通过实现存储的唯一标识符来判断文件是否之前已经被采集过。 如果在你的使用场景中,每天会产生大量的新文件,你将会发现Filebeat的注册表文件会变得非常大。这个时候,你可以参考(the section called “Registry file is too large?edit),来解决这个问题。安装filebeat服务二、ELK 常用架构及使用场景
2.1 最简单架构
在这种架构中,只有一个 Logstash、Elasticsearch 和 Kibana 实例。Logstash 通过输入插件从多种数据源(比如日志文件、标准输入 Stdin 等)获取数据,再经过滤插件加工数据,然后经 Elasticsearch 输出插件输出到 Elasticsearch,通过 Kibana 展示。详见图 1。 图 1. 最简单架构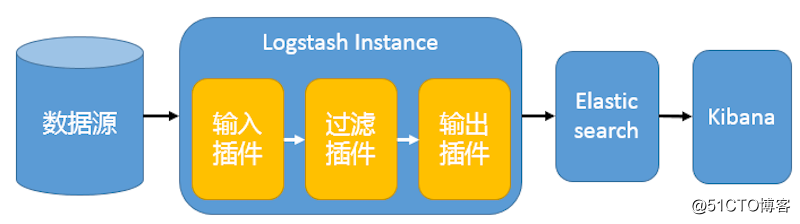 这种架构非常简单,使用场景也有限。初学者可以搭建这个架构,了解 ELK 如何工作。
这种架构非常简单,使用场景也有限。初学者可以搭建这个架构,了解 ELK 如何工作。 2.2 Logstash 作为日志搜集器
这种架构是对上面架构的扩展,把一个 Logstash 数据搜集节点扩展到多个,分布于多台机器,将解析好的数据发送到 Elasticsearch server 进行存储,最后在 Kibana 查询、生成日志报表等。详见图 2。 图 2. Logstash 作为日志搜索器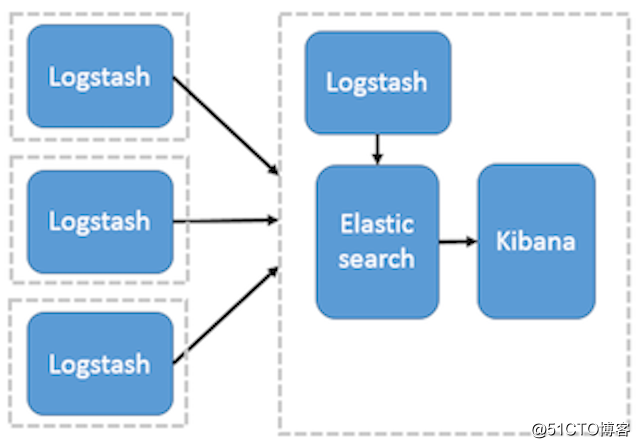 这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。
这种结构因为需要在各个服务器上部署 Logstash,而它比较消耗 CPU 和内存资源,所以比较适合计算资源丰富的服务器,否则容易造成服务器性能下降,甚至可能导致无法正常工作。 2.3 Beats 作为日志搜集器
这种架构引入 Beats 作为日志搜集器。目前 Beats 包括四种:Packetbeat(搜集网络流量数据);Topbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据);Filebeat(搜集文件数据);Winlogbeat(搜集 Windows 事件日志数据)。
Beats 将搜集到的数据发送到 Logstash,经 Logstash 解析、过滤后,将其发送到 Elasticsearch 存储,并由 Kibana 呈现给用户。详见图 3。
图 3. Beats 作为日志搜集器
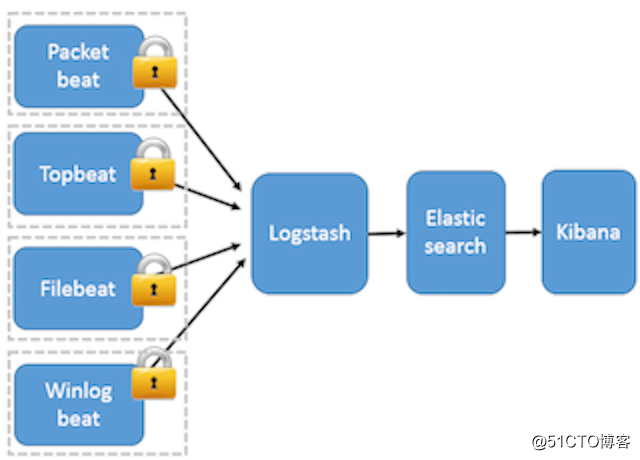 这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。 因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。
这种架构解决了 Logstash 在各服务器节点上占用系统资源高的问题。相比 Logstash,Beats 所占系统的 CPU 和内存几乎可以忽略不计。另外,Beats 和 Logstash 之间支持 SSL/TLS 加密传输,客户端和服务器双向认证,保证了通信安全。 因此这种架构适合对数据安全性要求较高,同时各服务器性能比较敏感的场景。 2.4 引入消息队列机制的架构
这种架构使用 Logstash 从各个数据源搜集数据,然后经消息队列输出插件输出到消息队列中。目前 Logstash 支持 Kafka、Redis、RabbitMQ 等常见消息队列。然后 Logstash 通过消息队列输入插件从队列中获取数据,分析过滤后经输出插件发送到 Elasticsearch,最后通过 Kibana 展示。详见图 4。图 4. 引入消息队列机制的架构
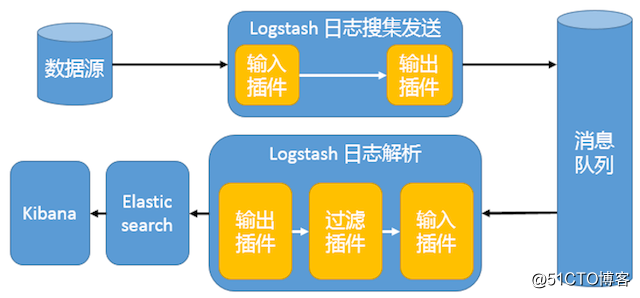
这种架构适合于日志规模比较庞大的情况。但由于 Logstash 日志解析节点和 Elasticsearch 的负荷比较重,可将他们配置为集群模式,以分担负荷。引入消息队列,均衡了网络传输,从而降低了网络闭塞,尤其是丢失数据的可能性,但依然存在 Logstash 占用系统资源过多的问题。
2.5 基于 Filebeat 架构的配置部署详解
前面提到 Filebeat 已经完全替代了 Logstash-Forwarder 成为新一代的日志采集器,同时鉴于它轻量、安全等特点,越来越多人开始使用它。这个章节将详细讲解如何部署基于 Filebeat 的 ELK 集中式日志解决方案,具体架构见图 5。图 5. 基于 Filebeat 的 ELK 集群架构
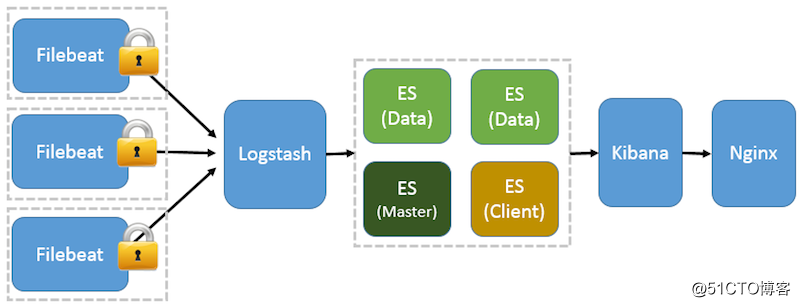
因为免费的 ELK 没有任何安全机制,所以这里使用了 Nginx 作反向代理,避免用户直接访问 Kibana 服务器。加上配置 Nginx 实现简单的用户认证,一定程度上提高安全性。另外,Nginx 本身具有负载均衡的作用,能够提高系统访问性能。
三、Filebeat安装
3.1下载和安装key文件
sudo rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch 3.2 创建yum源文件
[root@localhost ~]# vim /etc/yum.repos.d/elk-elasticsearch.repo[elastic-6.x]name=Elastic repository for 6.x packages baseurl=https://artifacts.elastic.co/packages/6.x/yum gpgcheck=1 gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch enabled=1 autorefresh=1 type=rpm-md
3.3 开始安装
sudo yum install filebeat 3.4 启动服务
sudo chkconfig --add filebeatsystemctl start filebeatsystemctl status filebeat
收集日志
这里我们先以收集docker日志为例,简单来介绍一下filebeat的配置文件该如何编写。具体内容如下:[root@localhost ~]# grep "^\s*[^# \t].*$" /etc/filebeat/filebeat.yml filebeat: prospectors: - input_type: log paths: - /data/logs/nginx/*.log input_type: log document_type: nginx close_inactive: 1m scan_frequency: 5s fields: nginx_id: web-nodejs fields_under_root: true close_removed: true tail_files: true tags: 'web-nginx' spool_size: 1024 idle_timeout: 5s registry_file: /var/lib/filebeat/registry output: logstash: enabled: true hosts: ["192.168.6.108:5044"] worker: 4 bulk_max_size: 1024 compression_level: 6 loadbalance: false index: filebeat backoff.max: 120s
和我们看的一样,其实并没有太多的内容。我们采集/var/lib/docker/containers//.log,即filebeat所在节点的所有容器的日志。输出的位置是我们ElasticSearch的服务地址,这里我们直接将log输送给ES,而不通过Logstash中转。
再启动之前,我们还需要向ES提交一个filebeat index template,以便让elasticsearch知道filebeat输出的日志数据都包含哪些属性和字段。filebeat.template.json这个文件安装完之后就有,无需自己编写,找不到的同学可以通过find查找。加载模板到elasticsearch中:
[root@localhost ~]# curl -XPUT 'http://192.168.58.128:9200/_template/filebeat?pretty' -d@/etc/filebeat/filebeat.template.json{ "acknowledged" : true} 重启服务
systemctl restart filebeat提示:如果你启动的是一个filebeat容器,需要将/var/lib/docker/containers目录挂载到该容器中; Kibana配置
如果上面配置都没有问题,就可以访问Kibana,不过这里需要添加一个新的index pattern。按照manual中的要求,对于filebeat输送的日志,我们的index name or pattern应该填写为:"filebeat-*"。
转自